
Det finns en tid före ChatGPT och en tid efter ChatGPT. Denna AI-tjänst har påverkat hur vi ser på AI och hur den kan hjälpa oss. Samtidigt är det kanske några som funderar på hur ChatGPT fungerar och varför just denna AI-chat-hjärna är så bra? I denna artikel försöker jag förklara den underliggande tekniken.
OBS Delar av denna artikel är skapad med hjälp av ChatGPT!
ChatGPT är en så kallad transformer-modell, en typ av maskininlärningsalgoritm som är utformad för att hantera textdata. Den är tränad på en mycket stor datamängd med text, till exempel böcker och artiklar, och har lärt sig att förstå och generera text på olika språk. Om vi ställer en fråga till ChatGPT, använder den den inlärda modellen för att konstruera ett svar eller en fortsättning på texten.
Maskininlärning
Maskininlärning är ett sätt att träna upp en matematisk modell på en större mängd data. Denna inlärning kan ske på flera sätt och två metoder som används för att träna ChatGPT är övervakad (“supervised”) och belöningsstyrd (“reinforced”) inlärning . Dessa två metoder kombineras i olika steg i inlärningsprocessen av ChatGPT.
I övervakad maskininlärning (“supervised”) så tränas modellen med hjälp av att data som i förväg klassificerats där vi ger processen både input och output, dvs., förväntat rätt svar till respektive input. Modellen lär sig att generera rätt output för ett givet input genom att förbättra sina parametrar och målet är att modellen ska kunna generalisera vidare och kunna förutsäga rätt output för ny input.
I belöningsstyrd (“reinforced”) maskininlärning ger vi modellen återkoppling i form av belöningar och straff utifrån fördefinierade regler. En agent som agerar utifrån modellen gör olika handlingar och får återkoppling för hur bra dessa fungerade. Detta är väldigt kraftfullt eftersom vi kan ge agenten väldigt få instruktioner och sedan får den helt enkelt gissa sig fram till vad som är rätt utifrån den återkoppling den får. I vissa applikationer är det lätt att ge snabb återkoppling medan i andra (som t.ex. schack) så kan det vara väldigt många steg tills den kan få någon belöning eller straff.
I följande exempel så har jag programmerat en enkel applikation för att träna upp en AI-hjärna med hjälp av belöningsstyrd maskininlärning. Målet är att hjärnan ska rulla en boll över en yta till kuben som dyker upp på olika ställen på ytan samt att bollen inte ska ramla ner. Belöningen är 1.0 om den träffar kuben och 0.1 om den i varje steg kommer närmare kuben. Straffet är -1.0 om den ramlar ner och -0.1 om den rör sig bort från kuben. Under träningen, får den som input hur långt från kuben den är och sina egna X,Y-koordinater. Vidare kan hjärnan putta på bollen i form av att ge den en fysisk knuff i samma plan. Jag har alltså inte explicit talat om att målet är att den ska träffa kuben utan det styrs helt av belöningssystemet. Applikationen är skapad och tränad i dataspelsmotorn Unity.
Hur tränas ChatGPT?
ChatGPT är tränad med hjälp av både övervakad och belöningsstyrd maskininlärning med tillägget att människor har varit inblandade i själva träningen i något som kallas “reinforcement learning from human feedback (RLHF)”, fritt översatt till belöningsstyrd maskininlärning med mänsklig återkoppling. Som namnet säger så är det människor som gett modellen återkoppling på vad som är bra respektive dåliga svar. Lite paradoxalt så är det människor som gjort delar, eller i alla fall hjälpt till med själva maskininlärningen. Detta är i sig inget nytt för första gången i just ChatGPT utan snarare det som är nytt är hur många människor som varit involverade. OpenAI, företaget bakom ChatGPT har inte sagt något om hur många som involverats men gissningsvis så har de lagt ner mycket pengar på just denna del av träningen i form av ersättning.
Följande information kommer primärt från OpenAI:s eget blogginlägg om ChatGPT och från publikationen om InstructGPT som ChatGPT baseras på.
ChatGPT har tränats i flera steg där de utgår ifrån en modell som tränats med övervakad maskininlärning och denna modell kallas GPT-3.5 som tränades klart i början av 2022 med data till ca mitten av 2021.
Steg 1
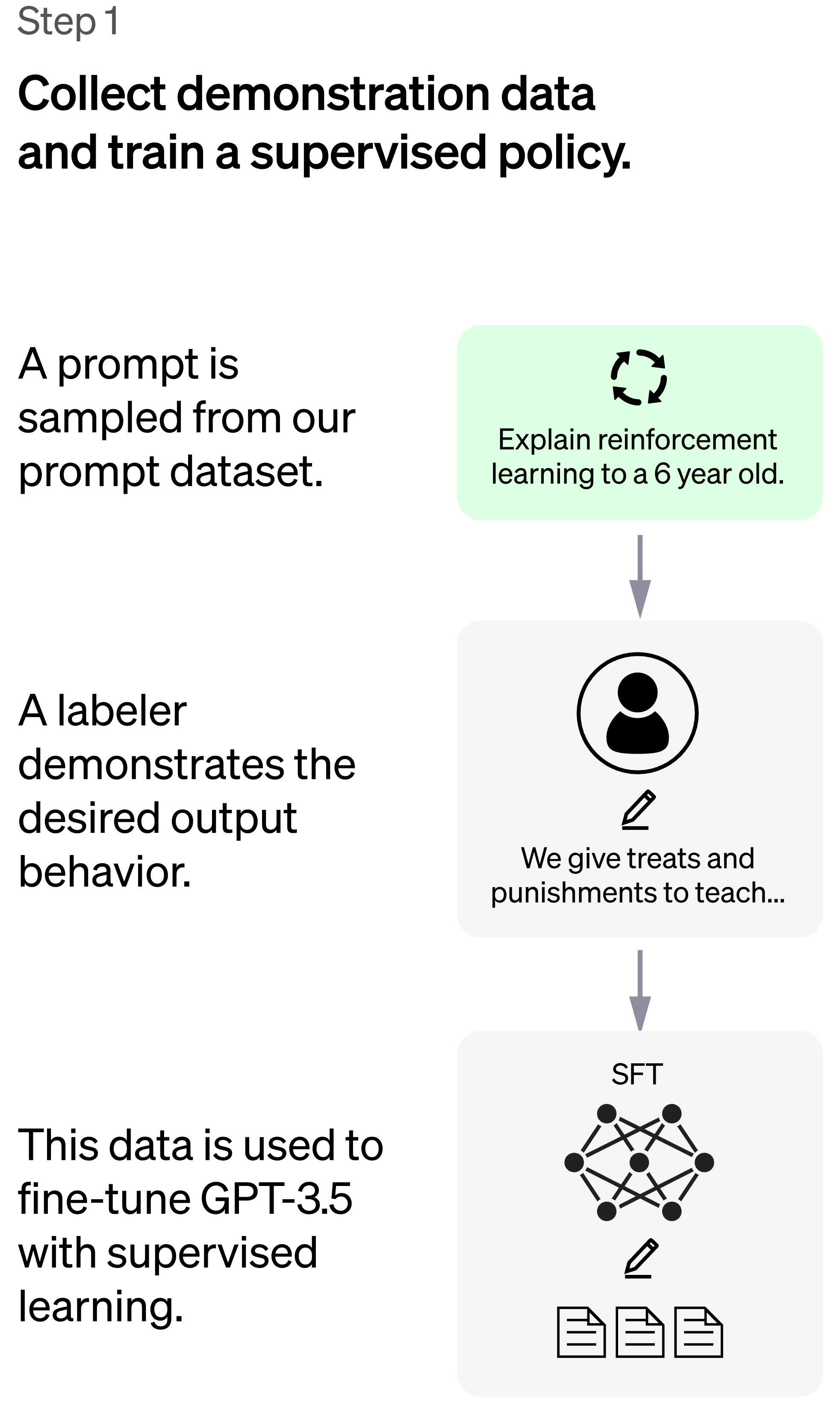
I steg 1 får människor skriva lämpliga svar på slumpmässigt utvalda frågor och dessa svar används för att skapa en bas för modellen som kallas SFT-modellen (“supervised fine-tuning model”). Frågorna kommer både från en pool av frågor som utvecklare (människor) skrivit för denna träning samt från frågor som användare av föregångaren till ChatGPT har skrivit i andra OpenAI-produkter. Bilderna nedan kommer från OpenAI:s blogginlägg om ChatGPT och jag har klippt upp en större bild i dessa tre delar.
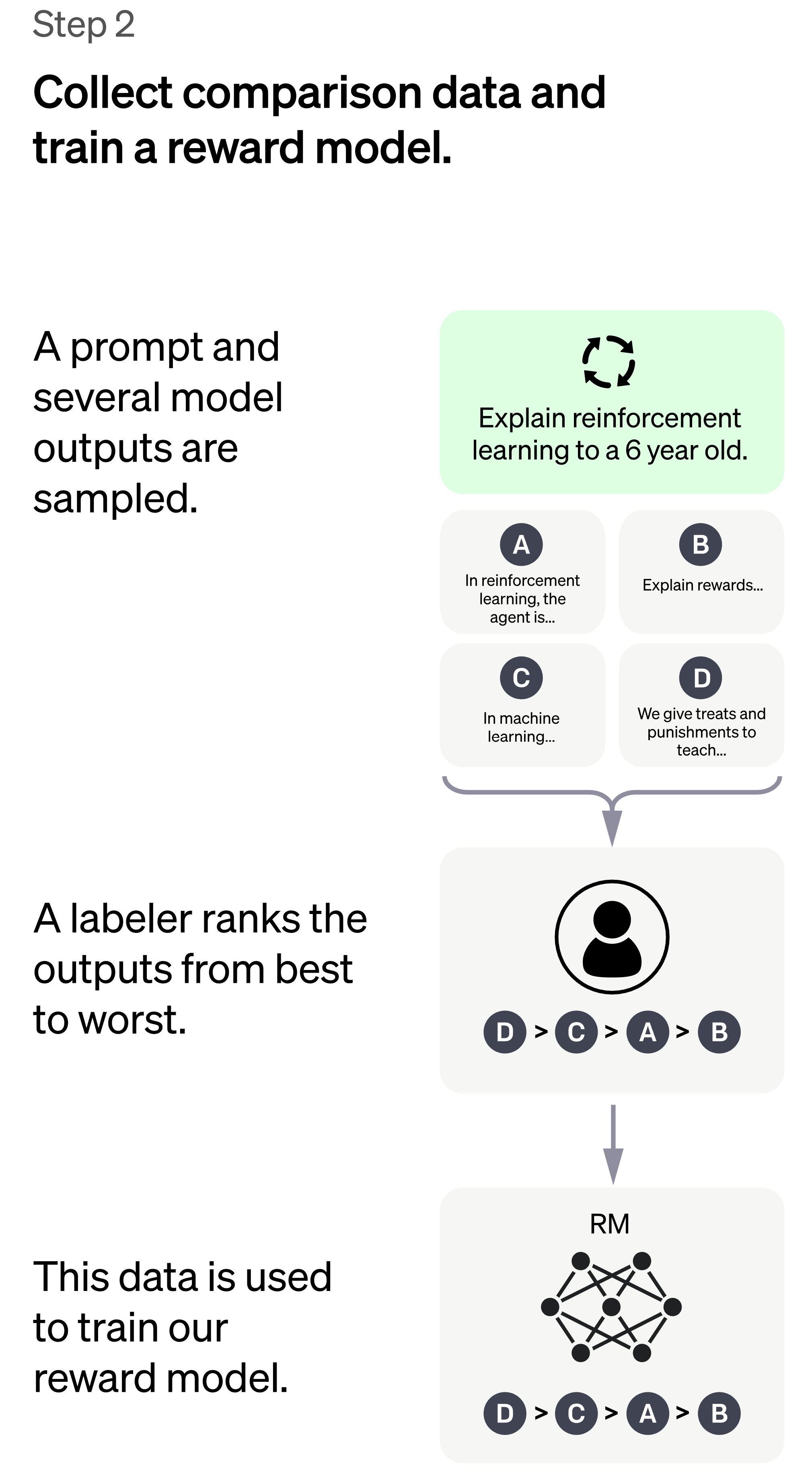
I steg 2 genererar ChatGPT flera svar (4-9 stycken) på olika frågor och människor får sedan klassificera dessa i förhållande till varandra och utifrån dessa skapas en ny modell för belöningar, RM-modellen (“reward model”). Denna kan ses som facit för ChatGPT för att hjälpa den lära sig vilka svar som faktiskt är bra. Detta steg genererar mänskligt data mycket fortare än steg 1 där människorna var tvungna att skriva hela svar själva. Resultatet från steg 2 är en modell för hur belöningarna ska delas ut i steg 3.
Steg 3
Det sista steget, steg 3 är var den stora träningen sker via belöningsstyrd maskininlärning. Här används något som heter Proximal Policy Optimization, PPO för att optimera belöningsmodellen där den finjusteras i varje steg. Dvs., för varje fråga/svar så optimerar den modellen.
Samtidigt justeras den inte för mycket, dvs., i varje steg kan den bara ändra belöningarna lite grann för att modellen inte ska blir helt trasig.
Exakt alla detaljer om hur denna träning går till har inte OpenAI avslöjat.
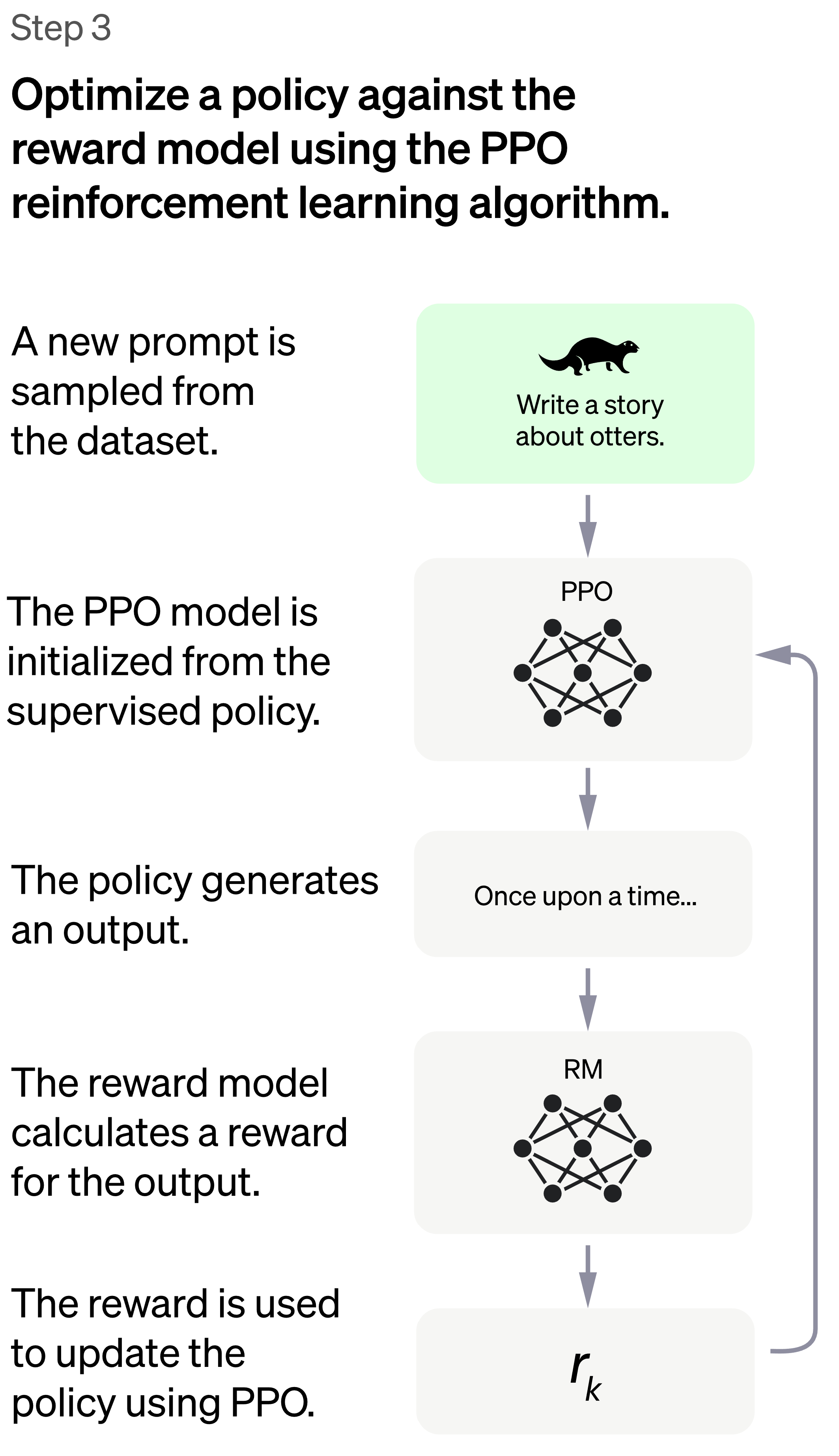
Steg 3 körs många gånger för att träna modellen och samtidigt finjustera belöningsmodellen.
Diskussion
Genom att involvera människor i processen så kan träningen bli mer korrekt utifrån mänskliga värderingar som är svåra att fånga via datorprogram. Slutresultatet har vi alla sett i form av ChatGPT som är minst sagt imponerande.
Begränsningar och problem
Tack vare att människor involveras så är det också stor risk att fördomar påverkar resultatet. Människor är involverade i både att skriva frågorna (till och med i andra produkter där de inte ens är medvetna om att de kommer att användas för träning) samt när svaren ska klassificeras för att skapa belöningsmodellen. Vidare är utvecklarna av modellen också människor som i sin tur påverkar resultatet. Sammantaget så är dessa inte representativa för en global användargrupp och utvecklare skriver själva om just denna begränsning.
Vidare händer det också att människorna inte är överens om hur svaren klassificeras i steg 2 och personliga åsikter kommer in i träningen. Här finns ingen faktisk sanning som kan vara avgörande om de inte är överens.
Alla som provar ChatGPT har säkert också identifierat flera problem med denna tjänst.
- Ibland ger ChatGPT oss svar som är helt eller delvis fel. Detta är svårt att träna bort eftersom ChatGPT helt enkelt tror att dessa svar är korrekta eftersom den inte har något facit.
- ChatGPT är väldigt känslig gällande hur vi formulerar våra frågor. Ibland kan en fråga ge svaret att den inte vet medan om vi ändra lite i frågan så får vi det svar vi eftersökte.
- ChatGPT är väldigt pratglad och ger oss ibland väldigt långa svar när en mening hade räckt. Anledningen till detta är delvis att människorna som klassificerade svaren i steg 2 föredrar utförliga svar eftersom de kändes mer rätt.
- ChatGPT frågar aldrig efter förtydliganden utan gissar vad vi vill veta och svarar på det. Ibland blir det skrämmande bra men ibland hade det varit bättre om den frågade tillbaka istället.
- ChatGPT ger oss inte förbjudna svar och det beror på att ChatGPT använder en annan tjänst “Moderation API” för att filtrera bort dåliga svar. Denna filtrering fungerar ibland för bra och plockar bort för mycket samtidigt som den ibland släpper igenom sådant som inte borde vara med. Här kan vi också diskutera vad som är lämpligt innehåll eftersom det i sin tur är kopplat till vår personliga kultur.
Framtiden
Även om ChatGPT (GPT3.5) är väldigt kraftfull så är detta bara ett första steg och vi kommer att få se mycket bättre modeller i framtiden. Både från OpenAI och från andra aktörer. Det som dock är klart är att dessa AI-modeller kostar otroligt mycket pengar att skapa i form av både mänsklig kraft och datorbaserad kraft. GPT 3.5 är för övrigt tränad på en superdator hos Microsofts Azure-infrastruktur och Microsoft satsar väldigt hårt på just ChatGPT och AI i sina produkter som jag tidigare skrivit om här.
Generellt är AI-verktygen här för att stanna och även om vissa jämför integration av ChatGPT i office med det klassiska gemet som fanns förr i tiden så är jag övertygad om att denna gång kommer vi att ha otroligt mycket mer nytta av denna medhjälpare.
Det område som jag tror kommer att revolutioneras mest är dock lärande där dessa AI-tjänster kommer att finnas med oss hela tiden och kunna motivera, hjälpa, stötta, förklara, utveckla och skräddarsy vårt lärande oberoende av vart vi är i livet, dvs., i det livslånga och kontinuerliga lärandet från födsel till död.

Vill ni att jag utvecklar något vidare eller har direkta frågor så maila mig. Jag har också flera föreläsningar planerade om ChatGPT under de kommande månaderna (Luleå och Stockholm) men vill ni att jag kommer och föreläser hos er så hör av er.
Som jag började denna artikel så har vi nu en skarp gräns mellan före ChatGPT och efter ChatGPT. Hoppas ni har inspirerats av denna artikel och har ni fortfarande inte provat ChatGPT så gör det nu!
One thought on “Hur fungerar ChatGPT?”